The purpose of the dataset interface is to provide a mechanism
to describe properties of datasets and to transfer data between
memory and disk. A dataset is composed of a collection of raw
data points and four classes of meta data to describe the data
points. The interface is hopefully designed in such a way as to
allow new features to be added without disrupting current
applications that use the dataset interface.
Each of these classes of meta data is handled differently by
the library although the same API might be used to create them.
For instance, the datatype exists as constant meta data and as
memory meta data; the same API (the H5T API) is
used to manipulate both pieces of meta data but they're handled
by the dataset API (the H5D API) in different
manners.
The dataset API partitions these terms on three orthogonal axes
(layout, compression, and external storage) and uses a
dataset creation property list to hold the various
settings and pass them through the dataset interface. This is
similar to the way HDF5 files are created with a file creation
property list. A dataset creation property list is always
derived from the default dataset creation property list (use
H5Pcreate() to get a copy of the default property
list) by modifying properties with various
H5Pset_property() functions.
Although it is most efficient if I/O requests are aligned on chunk
boundaries, this is not a constraint. The application can perform I/O
on any set of data points as long as the set can be described by the
data space. The set on which I/O is performed is called the
selection.
These functions set or query the deflate level of
dataset creation property list plist_id. The
H5Pset_deflate() sets the compression method to
H5Z_DEFLATE and sets the compression level to
some integer between one and nine (inclusive). One results in
the fastest compression while nine results in the best
compression ratio. The default value is six if
H5Pset_deflate() isn't called. The
H5Pget_deflate() returns the compression level
for the deflate method, or negative if the method is not the
deflate method.
4. External Storage Properties
Some storage formats may allow storage of data across a set of
non-HDF5 files. Currently, only the H5D_CONTIGUOUS storage
format allows external storage. A set segments (offsets and sizes) in
one or more files is defined as an external file list, or EFL,
and the contiguous logical addresses of the data storage are mapped onto
these segments.
herr_t H5Pset_external (hid_t plist, const
char *name, off_t offset, hsize_t
size)
- This function adds a new segment to the end of the external
file list of the specified dataset creation property list. The
segment begins a byte offset of file name and
continues for size bytes. The space represented by this
segment is adjacent to the space already represented by the external
file list. The last segment in a file list may have the size
H5F_UNLIMITED, in which case the external file may be
of unlimited size and no more files can be added to the external files list.
int H5Pget_external_count (hid_t plist)
- Calling this function returns the number of segments in an
external file list. If the dataset creation property list has no
external data then zero is returned.
herr_t H5Pget_external (hid_t plist, unsigned
idx, size_t name_size, char *name, off_t
*offset, hsize_t *size)
- This is the counterpart for the
H5Pset_external()
function. Given a dataset creation property list and a zero-based
index into that list, the file name, byte offset, and segment size are
returned through non-null arguments. At most name_size
characters are copied into the name argument which is not
null terminated if the file name is longer than the supplied name
buffer (this is similar to strncpy()).
Example: Multiple Segments
|
This example shows how a contiguous, one-dimensional dataset
is partitioned into three parts and each of those parts is
stored in a segment of an external file. The top rectangle
represents the logical address space of the dataset
while the bottom rectangle represents an external file.
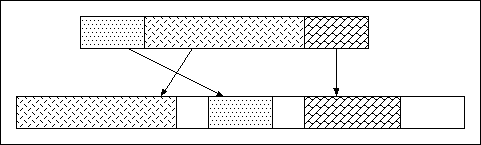
plist = H5Pcreate (H5P_DATASET_CREATE);
H5Pset_external (plist, "velocity.data", 3000, 1000);
H5Pset_external (plist, "velocity.data", 0, 2500);
H5Pset_external (plist, "velocity.data", 4500, 1500);
One should note that the segments are defined in order of the
logical addresses they represent, not their order within the
external file. It would also have been possible to put the
segments in separate files. Care should be taken when setting
up segments in a single file since the library doesn't
automatically check for segments that overlap.
|
Example: Multi-Dimensional
|
This example shows how a contiguous, two-dimensional dataset
is partitioned into three parts and each of those parts is
stored in a separate external file. The top rectangle
represents the logical address space of the dataset
while the bottom rectangles represent external files.
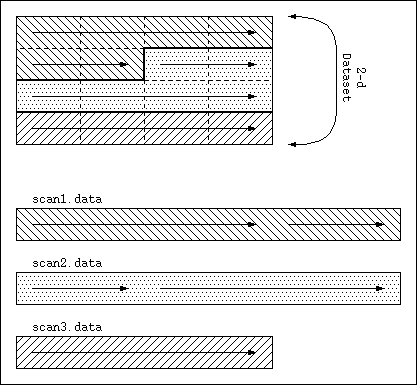
plist = H5Pcreate (H5P_DATASET_CREATE);
H5Pset_external (plist, "scan1.data", 0, 24);
H5Pset_external (plist, "scan2.data", 0, 24);
H5Pset_external (plist, "scan3.data", 0, 16);
The library maps the multi-dimensional array onto a linear
address space like normal, and then maps that address space
into the segments defined in the external file list.
|
The segments of an external file can exist beyond the end of the
file. The library reads that part of a segment as zeros. When writing
to a segment that exists beyond the end of a file, the file is
automatically extended. Using this feature, one can create a segment
(or set of segments) which is larger than the current size of the
dataset, which allows to dataset to be extended at a future time
(provided the data space also allows the extension).
All referenced external data files must exist before performing raw
data I/O on the dataset. This is normally not a problem since those
files are being managed directly by the application, or indirectly
through some other library.
5. Datatype
Raw data has a constant datatype which describes the datatype
of the raw data stored in the file, and a memory datatype that
describes the datatype stored in application memory. Both data
types are manipulated with the
H5T API.
The constant file datatype is associated with the dataset when
the dataset is created in a manner described below. Once
assigned, the constant datatype can never be changed.
The memory datatype is specified when data is transferred
to/from application memory. In the name of data sharability,
the memory datatype must be specified, but can be the same
type identifier as the constant datatype.
During dataset I/O operations, the library translates the raw
data from the constant datatype to the memory datatype or vice
versa. Structured datatypes include member offsets to allow
reordering of struct members and/or selection of a subset of
members and array datatypes include index permutation
information to allow things like transpose operations (the
prototype does not support array reordering) Permutations
are relative to some extrinsic descritpion of the dataset.
6. Data Space
The dataspace of a dataset defines the number of dimensions
and the size of each dimension and is manipulated with the
H5S API. The simple dataspace consists of
maximum dimension sizes and actual dimension sizes, which are
usually the same. However, maximum dimension sizes can be the
constant H5D_UNLIMITED in which case the actual
dimension size can be incremented with calls to
H5Dextend(). The maximium dimension sizes are
constant meta data while the actual dimension sizes are
persistent meta data. Initial actual dimension sizes are
supplied at the same time as the maximum dimension sizes when
the dataset is created.
The dataspace can also be used to define partial I/O
operations. Since I/O operations have two end-points, the raw
data transfer functions take two data space arguments: one which
describes the application memory data space or subset thereof
and another which describes the file data space or subset
thereof.
7. Setting Constant or Persistent Properties
Each dataset has a set of constant and persistent properties
which describe the layout method, pre-compression
transformation, compression method, datatype, external storage,
and data space. The constant properties are set as described
above in a dataset creation property list whose identifier is
passed to H5Dcreate().
hid_t H5Dcreate (hid_t file_id, const char
*name, hid_t type_id, hid_t
space_id, hid_t create_plist_id)
- A dataset is created by calling
H5Dcreate with
a file identifier, a dataset name, a datatype, a dataspace,
and constant properties. The datatype and dataspace are the
type and space of the dataset as it will exist in the file,
which may be different than in application memory.
Dataset names within a group must be unique:
H5Dcreate returns an error if a dataset with the
name specified in name already exists
at the location specified in file_id.
The create_plist_id is a H5P_DATASET_CREATE
property list created with H5Pcreate() and
initialized with the various functions described above.
H5Dcreate() returns a dataset handle for success
or negative for failure. The handle should eventually be
closed by calling H5Dclose() to release resources
it uses.
hid_t H5Dopen (hid_t file_id, const char
*name)
- An existing dataset can be opened for access by calling this
function. A dataset handle is returned for success or a
negative value is returned for failure. The handle should
eventually be closed by calling
H5Dclose() to
release resources it uses.
herr_t H5Dclose (hid_t dataset_id)
- This function closes a dataset handle and releases all
resources it might have been using. The handle should not be
used in subsequent calls to the library.
herr_t H5Dextend (hid_t dataset_id,
hsize_t dim[])
- This function extends a dataset by increasing the size in
one or more dimensions. Not all datasets can be extended.
8. Querying Constant or Persistent Properties
Constant or persistent properties can be queried with a set of
three functions. Each function returns an identifier for a copy
of the requested properties. The identifier can be passed to
various functions which modify the underlying object to derive a
new object; the original dataset is completely unchanged. The
return values from these functions should be properly destroyed
when no longer needed.
hid_t H5Dget_type (hid_t dataset_id)
- Returns an identifier for a copy of the dataset permanent
datatype or negative for failure.
hid_t H5Dget_space (hid_t dataset_id)
- Returns an identifier for a copy of the dataset permanent
data space, which also contains information about the current
size of the dataset if the data set is extendable with
H5Dextend().
hid_t H5Dget_create_plist (hid_t
dataset_id)
- Returns an identifier for a copy of the dataset creation
property list. The new property list is created by examining
various permanent properties of the dataset. This is mostly a
catch-all for everything but type and space.
9. Setting Memory and Transfer Properties
A dataset also has memory properties which describe memory
within the application, and transfer properties that control
various aspects of the I/O operations. The memory can have a
datatype different than the permanent file datatype (different
number types, different struct member offsets, different array
element orderings) and can also be a different size (memory is a
subset of the permanent dataset elements, or vice versa). The
transfer properties might provide caching hints or collective
I/O information. Therefore, each I/O operation must specify
memory and transfer properties.
The memory properties are specified with type_id and
space_id arguments while the transfer properties are
specified with the transfer_id property list for the
H5Dread() and H5Dwrite() functions
(these functions are described below).
herr_t H5Pset_buffer (hid_t xfer_plist,
hsize_t max_buf_size, void *tconv_buf, void
*bkg_buf)
hsize_t H5Pget_buffer (hid_t xfer_plist, void
**tconv_buf, void **bkg_buf)
- Sets or retrieves the maximum size in bytes of the temporary
buffer used for datatype conversion in the I/O pipeline. An
application-defined buffer can also be supplied as the
tconv_buf argument, otherwise a buffer will be
allocated and freed on demand by the library. A second
temporary buffer bkg_buf can also be supplied and
should be the same size as the tconv_buf. The
default values are 1MB for the maximum buffer size, and null
pointers for each buffer indicating that they should be
allocated on demand and freed when no longer needed. The
H5Pget_buffer() function returns the maximum
buffer size or zero on error.
If the maximum size of the temporary I/O pipeline buffers is
too small to hold the entire I/O request, then the I/O request
will be fragmented and the transfer operation will be strip
mined. However, certain restrictions apply to the strip
mining. For instance, when performing I/O on a hyperslab of a
simple data space the strip mining is in terms of the slowest
varying dimension. So if a 100x200x300 hyperslab is requested,
the temporary buffer must be large enough to hold a 1x200x300
sub-hyperslab.
To prevent strip mining from happening, the application should
use H5Pset_buffer() to set the size of the
temporary buffer so it's large enough to hold the entire
request.
Example
|
This example shows how to define a function that sets
a dataset transfer property list so that strip mining
does not occur. It takes an (optional) dataset transfer
property list, a dataset, a data space that describes
what data points are being transfered, and a datatype
for the data points in memory. It returns a (new)
dataset transfer property list with the temporary
buffer size set to an appropriate value. The return
value should be passed as the fifth argument to
H5Dread() or H5Dwrite().
1 hid_t
2 disable_strip_mining (hid_t xfer_plist, hid_t dataset,
3 hid_t space, hid_t mem_type)
4 {
5 hid_t file_type; /* File datatype */
6 size_t type_size; /* Sizeof larger type */
7 size_t size; /* Temp buffer size */
8 hid_t xfer_plist; /* Return value */
9
10 file_type = H5Dget_type (dataset);
11 type_size = MAX(H5Tget_size(file_type), H5Tget_size(mem_type));
12 H5Tclose (file_type);
13 size = H5Sget_npoints(space) * type_size;
14 if (xfer_plist<0) xfer_plist = H5Pcreate (H5P_DATASET_XFER);
15 H5Pset_buffer(xfer_plist, size, NULL, NULL);
16 return xfer_plist;
17 }
|
10. Querying Memory or Transfer Properties
Unlike constant and persistent properties, a dataset cannot be
queried for it's memory or transfer properties. Memory
properties cannot be queried because the application already
stores those properties separate from the buffer that holds the
raw data, and the buffer may hold multiple segments from various
datasets and thus have more than one set of memory properties.
The transfer properties cannot be queried from the dataset
because they're associated with the transfer itself and not with
the dataset (but one can call
H5Pget_property() to query transfer
properties from a tempalate).
11. Raw Data I/O
All raw data I/O is accomplished through these functions which
take a dataset handle, a memory datatype, a memory data space,
a file data space, transfer properties, and an application
memory buffer. They translate data between the memory datatype
and space and the file datatype and space. The data spaces can
be used to describe partial I/O operations.
herr_t H5Dread (hid_t dataset_id, hid_t
mem_type_id, hid_t mem_space_id, hid_t
file_space_id, hid_t xfer_plist_id,
void *buf/*out*/)
- Reads raw data from the specified dataset into buf
converting from file datatype and space to memory datatype
and space.
herr_t H5Dwrite (hid_t dataset_id, hid_t
mem_type_id, hid_t mem_space_id, hid_t
file_space_id, hid_t xfer_plist_id,
const void *buf)
- Writes raw data from an application buffer buf to
the specified dataset converting from memory datatype and
space to file datatype and space.
In the name of sharability, the memory datatype must be
supplied. However, it can be the same identifier as was used to
create the dataset or as was returned by
H5Dget_type(); the library will not implicitly
derive memory datatypes from constant datatypes.
For complete reads of the dataset one may supply
H5S_ALL as the argument for the file data space.
If H5S_ALL is also supplied as the memory data
space then no data space conversion is performed. This is a
somewhat dangerous situation since the file data space might be
different than what the application expects.
12. Examples
The examples in this section illustrate some common dataset
practices.
This example shows how to create a dataset which is stored in
memory as a two-dimensional array of native double
values but is stored in the file in Cray float
format using LZ77 compression. The dataset is written to the
HDF5 file and then read back as a two-dimensional array of
float values.
Example 1
|
1 hid_t file, data_space, dataset, properties;
2 double dd[500][600];
3 float ff[500][600];
4 hsize_t dims[2], chunk_size[2];
5
6 /* Describe the size of the array */
7 dims[0] = 500;
8 dims[1] = 600;
9 data_space = H5Screate_simple (2, dims);
10
11
12 /*
13 * Create a new file using with read/write access,
14 * default file creation properties, and default file
15 * access properties.
16 */
17 file = H5Fcreate ("test.h5", H5F_ACC_RDWR, H5P_DEFAULT,
18 H5P_DEFAULT);
19
20 /*
21 * Set the dataset creation plist to specify that
22 * the raw data is to be partitioned into 100x100 element
23 * chunks and that each chunk is to be compressed with
24 * LZ77.
25 */
26 chunk_size[0] = chunk_size[1] = 100;
27 properties = H5Pcreate (H5P_DATASET_CREATE);
28 H5Pset_chunk (properties, 2, chunk_size);
29 H5Pset_deflate (properties, 9);
30
31 /*
32 * Create a new dataset within the file. The datatype
33 * and data space describe the data on disk, which may
34 * be different than the format used in the application's
35 * memory.
36 */
37 dataset = H5Dcreate (file, "dataset", H5T_CRAY_FLOAT,
38 data_space, properties);
39
40 /*
41 * Write the array to the file. The datatype and data
42 * space describe the format of the data in the `dd'
43 * buffer. The raw data is translated to the format
44 * required on disk defined above. We use default raw
45 * data transfer properties.
46 */
47 H5Dwrite (dataset, H5T_NATIVE_DOUBLE, H5S_ALL, H5S_ALL,
48 H5P_DEFAULT, dd);
49
50 /*
51 * Read the array as floats. This is similar to writing
52 * data except the data flows in the opposite direction.
53 */
54 H5Dread (dataset, H5T_NATIVE_FLOAT, H5S_ALL, H5S_ALL,
55 H5P_DEFAULT, ff);
56
64 H5Dclose (dataset);
65 H5Sclose (data_space);
66 H5Pclose (properties);
67 H5Fclose (file);
|
This example uses the file created in Example 1 and reads a
hyperslab of the 500x600 file dataset. The hyperslab size is
100x200 and it is located beginning at element
<200,200>. We read the hyperslab into an 200x400 array in
memory beginning at element <0,0> in memory. Visually,
the transfer looks something like this:
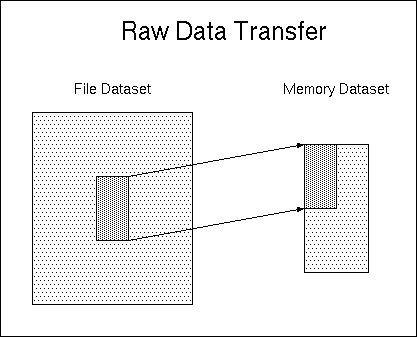
Example 2
|
1 hid_t file, mem_space, file_space, dataset;
2 double dd[200][400];
3 hsize_t offset[2];
4 hsize size[2];
5
6 /*
7 * Open an existing file and its dataset.
8 */
9 file = H5Fopen ("test.h5", H5F_ACC_RDONLY, H5P_DEFAULT);
10 dataset = H5Dopen (file, "dataset");
11
12 /*
13 * Describe the file data space.
14 */
15 offset[0] = 200; /*offset of hyperslab in file*/
16 offset[1] = 200;
17 size[0] = 100; /*size of hyperslab*/
18 size[1] = 200;
19 file_space = H5Dget_space (dataset);
20 H5Sselect_hyperslab (file_space, H5S_SELECT_SET, offset, NULL, size, NULL);
21
22 /*
23 * Describe the memory data space.
24 */
25 size[0] = 200; /*size of memory array*/
26 size[1] = 400;
27 mem_space = H5Screate_simple (2, size);
28
29 offset[0] = 0; /*offset of hyperslab in memory*/
30 offset[1] = 0;
31 size[0] = 100; /*size of hyperslab*/
32 size[1] = 200;
33 H5Sselect_hyperslab (mem_space, H5S_SELECT_SET, offset, NULL, size, NULL);
34
35 /*
36 * Read the dataset.
37 */
38 H5Dread (dataset, H5T_NATIVE_DOUBLE, mem_space,
39 file_space, H5P_DEFAULT, dd);
40
41 /*
42 * Close/release resources.
43 */
44 H5Dclose (dataset);
45 H5Sclose (mem_space);
46 H5Sclose (file_space);
47 H5Fclose (file);
|
If the file contains a compound data structure one of whose
members is a floating point value (call it "delta") but the
application is interested in reading an array of floating point
values which are just the "delta" values, then the application
should cast the floating point array as a struct with a single
"delta" member.
Example 3
|
1 hid_t file, dataset, type;
2 double delta[200];
3
4 /*
5 * Open an existing file and its dataset.
6 */
7 file = H5Fopen ("test.h5", H5F_ACC_RDONLY, H5P_DEFAULT);
8 dataset = H5Dopen (file, "dataset");
9
10 /*
11 * Describe the memory datatype, a struct with a single
12 * "delta" member.
13 */
14 type = H5Tcreate (H5T_COMPOUND, sizeof(double));
15 H5Tinsert (type, "delta", 0, H5T_NATIVE_DOUBLE);
16
17 /*
18 * Read the dataset.
19 */
20 H5Dread (dataset, type, H5S_ALL, H5S_ALL,
21 H5P_DEFAULT, dd);
22
23 /*
24 * Close/release resources.
25 */
26 H5Dclose (dataset);
27 H5Tclose (type);
28 H5Fclose (file);
|
THG Help Desk: 
Describes HDF5 Release 1.4.5, February 2003
Last modified: 2 March 2001