|
HDF5 Last Updated on 2026-07-11
The HDF5 Field Guide
|
|
HDF5 Last Updated on 2026-07-11
The HDF5 Field Guide
|
Navigate back: Main / Getting Started with HDF5 / A Brief Introduction to Parallel HDF5
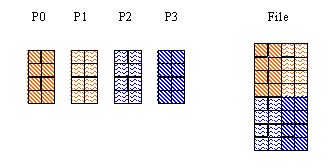
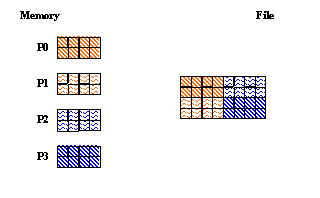
In this example each process writes a "chunk" of data to a dataset. The C and Fortran 90 examples result in the same data layout in the file.
| Figure a C Example | Figure b Fortran Example |
|---|---|
| 
|
For this example, four processes are used, and a 4 x 2 chunk is written to the dataset by each process.
To do this, you would:
| C | Process 0 | Process 1 | Process 2 | Process 3 |
|---|---|---|---|---|
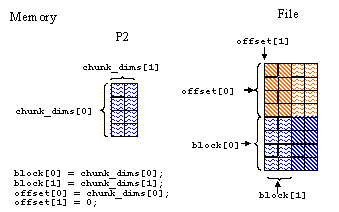
| offset[0] = 0 | offset[0] = 0 | offset[0] = 4 | offset[0] = 4 | |
| offset[1] = 0 | offset[1] = 2 | offset[1] = 0 | offset[1] = 2 | |
| Fortran | Process 0 | Process 1 | Process 2 | Process 3 |
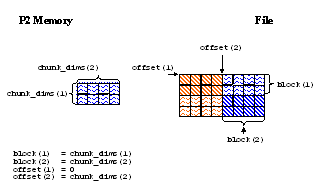
| offset(1) = 0 | offset(1) = 2 | offset(1) = 0 | offset(1) = 2 | |
| offset(2) = 0 | offset(2) = 0 | offset(2) = 4 | offset(2) = 4 |
For example, the offset and block parameters for Process 2 would look like:
| Figure a C Example | Figure b Fortran Example |
|---|---|
| 
|
Below are example programs for writing hyperslabs by pattern in Parallel HDF5:
| hyperslab_by_chunk.c |
| hyperslab_by_chunk.F90 |
The following is the output from h5dump for the HDF5 file created in this example:
The h5dump utility is written in C so the output is in C order.
Navigate back: Main / Getting Started with HDF5 / A Brief Introduction to Parallel HDF5