|
HDF5 Last Updated on 2026-07-11
The HDF5 Field Guide
|
|
HDF5 Last Updated on 2026-07-11
The HDF5 Field Guide
|
Navigate back: Main / Getting Started with HDF5
If you are new to HDF5 please see the Learning the Basics topic first.
There were several requirements that we had for Parallel HDF5 (PHDF5). These were:
With these requirements of HDF5 our initial target was to support MPI programming, but not for shared memory programming. We had done some experimentation with thread-safe support for Pthreads and for OpenMP, and decided to use these.
Implementation requirements were to:
The following shows the Parallel HDF5 implementation layers:
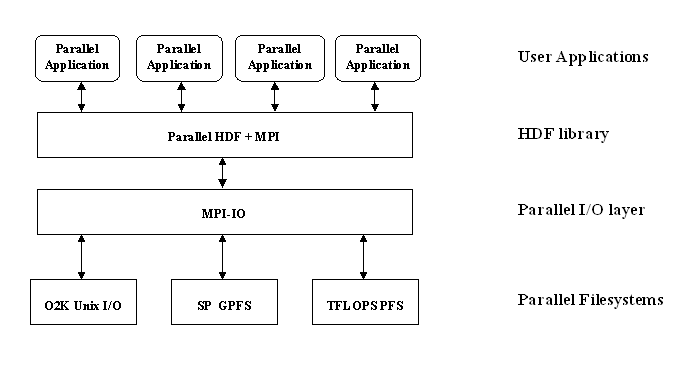
|
This tutorial assumes that you are somewhat familiar with parallel programming with MPI (Message Passing Interface).
If you are not familiar with parallel programming, here is a tutorial that may be of interest: Tutorial on HDF5 I/O tuning at NERSC (PDF). (NOTE: As of 2024, the specific systems described in this tutorial are outdated.)
Some of the terms that you must understand in this tutorial are:
MPI Communicator Allows a group of processes to communicate with each other.
Following are the MPI routines for initializing MPI and the communicator and finalizing a session with MPI:
| C | Fortran | Description |
|---|---|---|
| MPI_Init | MPI_INIT | Initialize MPI (MPI_COMM_WORLD usually) |
| MPI_Comm_size | MPI_COMM_SIZE | Define how many processes are contained in the communicator |
| MPI_Comm_rank | MPI_COMM_RANK | Define the process ID number within the communicator (from 0 to n-1) |
| MPI_Finalize | MPI_FINALIZE | Exiting MPI |
Parallel HDF5 opens a parallel file with a communicator. It returns a file handle to be used for future access to the file.
All processes are required to participate in the collective Parallel HDF5 API. Different files can be opened using different communicators.
Examples of what you can do with the Parallel HDF5 collective API:
Once a file is opened by the processes of a communicator:
Please refer to the Supported Configuration Features Summary in the release notes for the current release of HDF5 for an up-to-date list of the platforms that we support Parallel HDF5 on.
The programming model for creating and accessing a file is as follows:
Each process of the MPI communicator creates an access template and sets it up with MPI parallel access information. This is done with the H5Pcreate call to obtain the file access property list and the H5Pset_fapl_mpio call to set up parallel I/O access.
Following is example code for creating an access template in HDF5: C
Fortran
The following example programs create an HDF5 file using Parallel HDF5:
The programming model for creating and accessing a dataset is as follows:
Then set the data transfer mode to either use independent I/O access or to use collective I/O, with a call to: H5Pset_dxpl_mpio
Following are the parameters required by this call: C
Fortran
Access the dataset with the defined transfer property list. All processes that have opened a dataset may do collective I/O. Each process may do an independent and arbitrary number of data I/O access calls, using: H5Dwrite H5Dread
If a dataset is unlimited, you can extend it with a collective call to: H5Dextend
The following code demonstrates a collective write using Parallel HDF5: C
Fortran
The following example programs create an HDF5 dataset using Parallel HDF5:
The programming model for writing and reading hyperslabs is: /li Each process defines the memory and file hyperslabs. /li Each process executes a partial write/read call which is either collective or independent.
The memory and file hyperslabs in the first step are defined with the H5Sselect_hyperslab.
The start (or offset), count, stride, and block parameters define the portion of the dataset to write to. By changing the values of these parameters you can write hyperslabs with Parallel HDF5 by contiguous hyperslab, by regularly spaced data in a column/row, by patterns, and by chunks:
Navigate back: Main / Getting Started with HDF5