|
HDF5 Last Updated on 2026-07-19
The HDF5 Field Guide
|
|
HDF5 Last Updated on 2026-07-19
The HDF5 Field Guide
|
Navigate back: Main / HDF5 User Guide
The HDF5 library implements the HDF5 abstract data model and storage model. These models were described in the preceding chapter.
Two major objectives of the HDF5 products are to provide tools that can be used on as many computational platforms as possible (portability), and to provide a reasonably object-oriented data model and programming interface.
To be as portable as possible, the HDF5 library is implemented in portable C. C is not an object-oriented language, but the library uses several mechanisms and conventions to implement an object model.
One mechanism the HDF5 library uses is to implement the objects as data structures. To refer to an object, the HDF5 library implements its own pointers. These pointers are called identifiers. An identifier is then used to invoke operations on a specific instance of an object. For example, when a group is opened, the API returns a group identifier. This identifier is a reference to that specific group and will be used to invoke future operations on that group. The identifier is valid only within the context it is created and remains valid until it is closed or the file is closed. This mechanism is essentially the same as the mechanism that C++ or other object-oriented languages use to refer to objects except that the syntax is C.
Similarly, object-oriented languages collect all the methods for an object in a single name space. An example is the methods of a C++ class. The C language does not have any such mechanism, but the HDF5 library simulates this through its API naming convention. API function names begin with a common prefix that is related to the class of objects that the function operates on. The table below lists the HDF5 objects and the standard prefixes used by the corresponding HDF5 APIs. For example, functions that operate on datatype objects all have names beginning with H5T.
| Prefix | Operates on |
|---|---|
| Attributes (H5A) | Attributes |
| Datasets (H5D) | Datasets |
| Error Handling (H5E) | Error reports |
| Files (H5F) | Files |
| Groups (H5G) | Groups |
| Identifiers (H5I) | Identifiers |
| Links (H5L) | Links |
| Objects (H5O) | Objects |
| Property Lists (H5P) | Property lists |
| References (H5R) | References |
| Dataspaces (H5S) | Dataspaces |
| Datatypes (H5T) | Datatypes |
| Filters (H5Z) | Filters |
In this section we introduce the HDF5 programming model by means of a series of short code samples. These samples illustrate a broad selection of common HDF5 tasks. More details are provided in the following chapters and in the HDF5 Reference Manual.
Before an HDF5 file can be used or referred to in any manner, it must be explicitly created or opened. When the need for access to a file ends, the file must be closed. The example below provides a C code fragment illustrating these steps. In this example, the values for the file creation property list and the file access property list are set to the defaults H5P_DEFAULT.
Creating and closing an HDF5 file
Note: If there is a possibility that a file of the declared name already exists and you wish to open a new file regardless of that possibility, the flag H5F_ACC_TRUNC will cause the operation to overwrite the previous file. If the operation should fail in such a circumstance, use the flag H5F_ACC_EXCL instead.
The essential objects within a dataset are datatype and dataspace. These are independent objects and are created separately from any dataset to which they may be attached. Hence, creating a dataset requires, at a minimum, the following steps:
The code in the example below illustrates the execution of these steps.
Create a dataset
An application should close an object such as a datatype, dataspace, or dataset once the object is no longer needed. Since each is an independent object, each must be released (or closed) separately. This action is frequently referred to as releasing the object's identifier. The code in the example below closes the datatype, dataspace, and dataset that were created in the preceding section.
Close an object
There is a long list of HDF5 library items that return a unique identifier when the item is created or opened. Each time that one of these items is opened, a unique identifier is returned. Closing a file does not mean that the groups, datasets, or other open items are also closed. Each opened item must be closed separately.
For more information,
Every structural element in an HDF5 file can be opened, and these elements can be opened more than once. Elements range in size from the entire file down to attributes. When an element is opened, the HDF5 library returns a unique identifier to the application. Every element that is opened must be closed. If an element was opened more than once, each identifier that was returned to the application must be closed. For example, if a dataset was opened twice, both dataset identifiers must be released (closed) before the dataset can be considered closed. Suppose an application has opened a file, a group in the file, and two datasets in the group. In order for the file to be totally closed, the file, group, and datasets must each be closed. Closing the file before the group or the datasets will not affect the state of the group or datasets: the group and datasets will still be open.
There are several exceptions to the above general rule. One is when the H5close function is used. H5close causes a general shutdown of the library: all data is written to disk, all identifiers are closed, and all memory used by the library is cleaned up. Another exception occurs on parallel processing systems. Suppose on a parallel system an application has opened a file, a group in the file, and two datasets in the group. If the application uses the H5Fclose function to close the file, the call will fail with an error. The open group and datasets must be closed before the file can be closed. A third exception is when the file access property list includes the property H5F_CLOSE_STRONG. This property closes any open elements when the file is closed with H5Fclose. For more information, see the H5Pset_fclose_degree function in the HDF5 Reference Manual.
Having created the dataset, the actual data can be written with a call to H5Dwrite. See the example below.
Writing a dataset
Note that the third and fourth H5Dwrite parameters in the above example describe the dataspaces in memory and in the file, respectively. For now, these are both set to H5S_ALL which indicates that the entire dataset is to be written. The selection of partial datasets and the use of differing dataspaces in memory and in storage will be discussed later in this chapter and in more detail elsewhere in this guide.
Reading the dataset from storage is similar to writing the dataset to storage. To read an entire dataset, substitute H5Dread for H5Dwrite in the above example.
The previous section described writing or reading an entire dataset. HDF5 also supports access to portions of a dataset. These parts of datasets are known as selections.
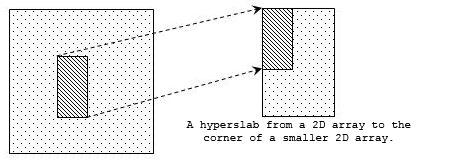
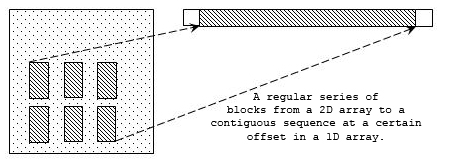
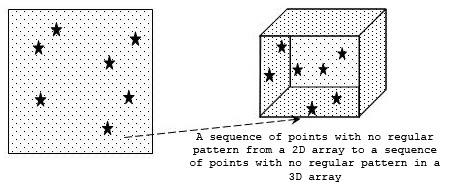
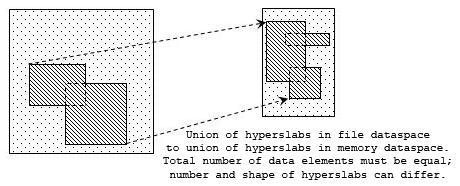
The simplest type of selection is a simple hyperslab. This is an n-dimensional rectangular sub-set of a dataset where n is equal to the dataset's rank. Other available selections include a more complex hyperslab with user-defined stride and block size, a list of independent points, or the union of any of these.
The figure below shows several sample selections.
|
|
|

|
Note: In the figure above, selections can take the form of a simple hyperslab, a hyperslab with user-defined stride and block, a selection of points, or a union of any of these forms.
Selections and hyperslabs are portions of a dataset. As described above, a simple hyperslab is a rectangular array of data elements with the same rank as the dataset's dataspace. Thus, a simple hyperslab is a logically contiguous collection of points within the dataset.
The more general case of a hyperslab can also be a regular pattern of points or blocks within the dataspace. Four parameters are required to describe a general hyperslab: the starting coordinates, the block size, the stride or space between blocks, and the number of blocks. These parameters are each expressed as a one-dimensional array with length equal to the rank of the dataspace and are described in the table below.
| Parameter | Definition |
|---|---|
| start | The coordinates of the starting location of the hyperslab in the dataset's dataspace. |
| block | The size of each block to be selected from the dataspace. If the block parameter is set to NULL, the block size defaults to a single element in each dimension, as if the block array was set to all 1s (all ones). This will result in the selection of a uniformly spaced set of count points starting at start and on the interval defined by stride. |
| stride | The number of elements separating the starting point of each element or block to be selected. If the stride parameter is set to NULL, the stride size defaults to 1 (one) in each dimension and no elements are skipped. |
| count | The number of elements or blocks to select along each dimension. |
For maximum flexibility in user applications, a selection in storage can be mapped into a differently-shaped selection in memory. All that is required is that the two selections contain the same number of data elements. In this example, we will first define the selection to be read from the dataset in storage, and then we will define the selection as it will appear in application memory.
Suppose we want to read a 3 x 4 hyperslab from a two-dimensional dataset in a file beginning at the dataset element <1,2>. The first task is to create the dataspace that describes the overall rank and dimensions of the dataset in the file and to specify the position and size of the in-file hyperslab that we are extracting from that dataset. See the code below.
Define the selection to be read from storage
The next task is to define a dataspace in memory. Suppose that we have in memory a three-dimensional 7 x 7 x 3 array into which we wish to read the two-dimensional 3 x 4 hyperslab described above and that we want the memory selection to begin at the element <3,0,0> and reside in the plane of the first two dimensions of the array. Since the in-memory dataspace is three-dimensional, we have to describe the in-memory selection as three-dimensional. Since we are keeping the selection in the plane of the first two dimensions of the in-memory dataset, the in-memory selection will be a 3 x 4 x 1 array defined as <3,4,1>.
Notice that we must describe two things: the dimensions of the in-memory array, and the size and position of the hyperslab that we wish to read in. The code below illustrates how this would be done.
Define the memory dataspace and selection
The hyperslab defined in the code above has the following parameters: start=(3,0,0), count=(3,4,1), stride and block size are NULL.
Now let's consider the opposite process of writing a selection from memory to a selection in a dataset in a file. Suppose that the source dataspace in memory is a 50-element, one-dimensional array called vector and that the source selection is a 48-element simple hyperslab that starts at the second element of vector. See the figure below.

A one-dimensional array |
Further suppose that we wish to write this data to the file as a series of 3 x 2-element blocks in a two-dimensional dataset, skipping one row and one column between blocks. Since the source selection contains 48 data elements and each block in the destination selection contains 6 data elements, we must define the destination selection with 8 blocks. We will write 2 blocks in the first dimension and 4 in the second. The code below shows how to achieve this objective.
The destination selection
Although reading is analogous to writing, it is often first necessary to query a file to obtain information about the dataset to be read. For instance, we often need to determine the datatype associated with a dataset, or its dataspace (in other words, rank and dimensions). As illustrated in the code example below, there are several get routines for obtaining this information.
Routines to get dataset parameters
A compound datatype is a collection of one or more data elements. Each element might be an atomic type, a small array, or another compound datatype.
The provision for nested compound datatypes allows these structures to become quite complex. An HDF5 compound datatype has some similarities to a C struct or a Fortran common block. Though not originally designed with databases in mind, HDF5 compound datatypes are sometimes used in a way that is similar to a database record. Compound datatypes can become either a powerful tool or a complex and difficult-to-debug construct. Reasonable caution is advised.
To create and use a compound datatype, you need to create a datatype with class compound (H5T_COMPOUND) and specify the total size of the data element in bytes. A compound datatype consists of zero or more uniquely named members. Members can be defined in any order but must occupy non-overlapping regions within the datum. The table below lists the properties of compound datatype members.
| Parameter | Definition |
|---|---|
| Index | An index number between zero and N-1, where N is the number of members in the compound. The elements are indexed in the order of their location in the array of bytes. |
| Name | A string that must be unique within the members of the same datatype. |
| Datatype | An HDF5 datatype. |
| Offset | A fixed byte offset which defines the location of the first byte of that member in the compound datatype. |
Properties of the members of a compound datatype are defined when the member is added to the compound type. These properties cannot be modified later.
Compound datatypes must be built out of other datatypes. To do this, you first create an empty compound datatype and specify its total size. Members are then added to the compound datatype in any order.
Each member must have a descriptive name. This is the key used to uniquely identify the member within the compound datatype. A member name in an HDF5 datatype does not necessarily have to be the same as the name of the corresponding member in the C struct in memory although this is often the case. You also do not need to define all the members of the C struct in the HDF5 compound datatype (or vice versa).
Usually a C struct will be defined to hold a data point in memory, and the offsets of the members in memory will be the offsets of the struct members from the beginning of an instance of the struct. The library defines the macro that computes the offset of member m within a struct variable s:
The code below shows an example in which a compound datatype is created to describe complex numbers whose type is defined by the complex_t struct.
A compound datatype for complex numbers
An extendable dataset is one whose dimensions can grow. One can define an HDF5 dataset to have certain initial dimensions with the capacity to later increase the size of any of the initial dimensions. For example, the figure below shows a 3 x 3 dataset (a) which is later extended to be a 10 x 3 dataset by adding 7 rows (b), and further extended to be a 10 x 5 dataset by adding two columns (c).
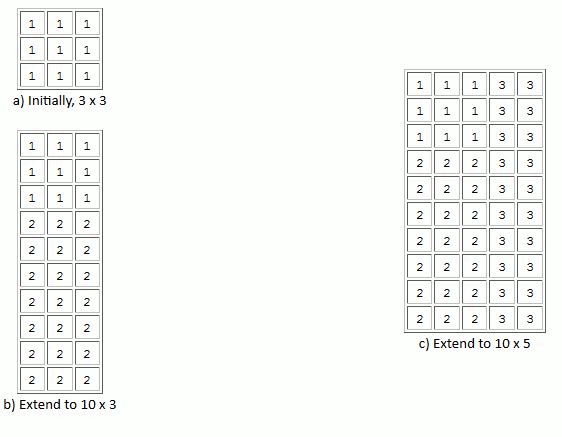
Extending a dataset |
HDF5 requires the use of chunking when defining extendable datasets. Chunking in HDF5 makes it possible to extend datasets efficiently without having to reorganize contiguous storage excessively.
To summarize, an extendable dataset requires two conditions:
For example, suppose we wish to create a dataset similar to the one shown in the figure above. We want to start with a 3 x 3 dataset, and then later we will extend it. To do this, go through the steps below.
First, declare the dataspace to have unlimited dimensions. See the code shown below. Note the use of the predefined constant H5S_UNLIMITED to specify that a dimension is unlimited.
Declaring a dataspace with unlimited dimensions
Next, set the dataset creation property list to enable chunking. See the code below.
Enable chunking
The next step is to create the dataset. See the code below.
Create a dataset
Finally, when the time comes to extend the size of the dataset, invoke H5Dextend. Extending the dataset along the first dimension by seven rows leaves the dataset with new dimensions of <10,3>. See the code below.
Extend the dataset by seven rows
Groups provide a mechanism for organizing meaningful and extendable sets of datasets within an HDF5 file. The Groups (H5G) API provides several routines for working with groups.
With no datatype, dataspace, or storage layout to define, creating a group is considerably simpler than creating a dataset. For example, the following code creates a group called Data in the root group of file.
Create a group
A group may be created within another group by providing the absolute name of the group to the H5Gcreate function or by specifying its location. For example, to create the group Data_new in the group Data, you might use the sequence of calls shown below.
Create a group within a group
This first parameter of H5Gcreate is a location identifier. file in the first example specifies only the file. grp in the second example specifies a particular group in a particular file. Note that in this instance, the group identifier grp is used as the first parameter in the H5Gcreate call so that the relative name of Data_new can be used.
The third parameter of H5Gcreate optionally specifies how much file space to reserve to store the names of objects that will be created in this group. If a non-positive value is supplied, the library provides a default size.
Use H5Gclose to close the group and release the group identifier.
As with groups, a dataset can be created in a particular group by specifying either its absolute name in the file or its relative name with respect to that group. The next code excerpt uses the absolute name.
Create a dataset within a group using a relative name
Alternatively, you can first obtain an identifier for the group in which the dataset is to be created, and then create the dataset with a relative name.
Create a dataset within a group using a relative name
Any object in a group can be accessed by its absolute or relative name. The first code snippet below illustrates the use of the absolute name to access the dataset Compressed_Data in the group Data created in the examples above. The second code snippet illustrates the use of the relative name.
Accessing a group using its relative name
An attribute is a small dataset that is attached to a normal dataset or group. Attributes share many of the characteristics of datasets, so the programming model for working with attributes is similar in many ways to the model for working with datasets. The primary differences are that an attribute must be attached to a dataset or a group and sub-setting operations cannot be performed on attributes.
To create an attribute belonging to a particular dataset or group, first create a dataspace for the attribute with the call to H5Screate, and then create the attribute using H5Acreate. For example, the code shown below creates an attribute called “Integer attribute” that is a member of a dataset whose identifier is dataset. The attribute identifier is attr2. H5Awrite then sets the value of the attribute of that of the integer variable point. H5Aclose then releases the attribute identifier.
Create an attribute
Read a known attribute
To read a scalar attribute whose name and datatype are known, first open the attribute using H5Aopen_by_name, and then use H5Aread to get its value. For example, the code shown below reads a scalar attribute called “Integer attribute” whose datatype is a native integer and whose parent dataset has the identifier dataset.
To read an attribute whose characteristics are not known, go through these steps. First, query the file to obtain information about the attribute such as its name, datatype, rank, and dimensions, and then read the attribute. The following code opens an attribute by its index value using H5Aopen_by_idx, and then it reads in information about the datatype with H5Aread.
Read an unknown attribute
In practice, if the characteristics of attributes are not known, the code involved in accessing and processing the attribute can be quite complex. For this reason, HDF5 includes a function called H5Aiterate. This function applies a user-supplied function to each of a set of attributes. The user-supplied function can contain the code that interprets, accesses, and processes each attribute.
The HDF5 library implements data transfers between different storage locations. At the lowest levels, the HDF5 Library reads and writes blocks of bytes to and from storage using calls to the virtual file layer (VFL) drivers. In addition to this, the HDF5 library manages caches of metadata and a data I/O pipeline. The data I/O pipeline applies compression to data blocks, transforms data elements, and implements selections.
A substantial portion of the HDF5 library's work is in transferring data from one environment or media to another. This most often involves a transfer between system memory and a storage medium. Data transfers are affected by compression, encryption, machine-dependent differences in numerical representation, and other features. So, the bit-by-bit arrangement of a given dataset is often substantially different in the two environments.
Consider the representation on disk of a compressed and encrypted little-endian array as compared to the same array after it has been read from disk, decrypted, decompressed, and loaded into memory on a big-endian system. HDF5 performs all of the operations necessary to make that transition during the I/O process with many of the operations being handled by the VFL and the data transfer pipeline.
The figure below provides a simplified view of a sample data transfer with four stages. Note that the modules are used only when needed. For example, if the data is not compressed, the compression stage is omitted.
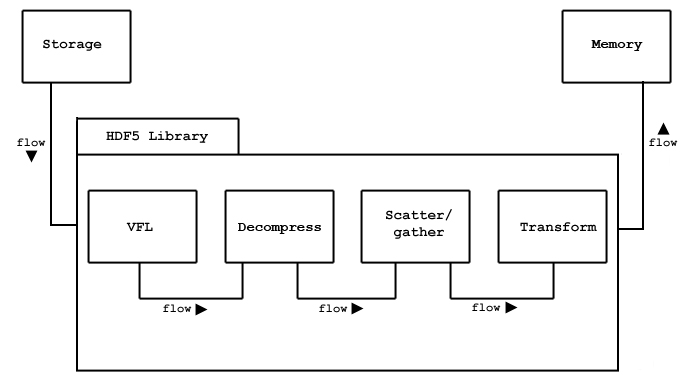
A data transfer from storage to memory |
For a given I/O request, different combinations of actions may be performed by the pipeline. The library automatically sets up the pipeline and passes data through the processing steps. For example, for a read request (from disk to memory), the library must determine which logical blocks contain the requested data elements and fetch each block into the library's cache. If the data needs to be decompressed, then the compression algorithm is applied to the block after it is read from disk. If the data is a selection, the selected elements are extracted from the data block after it is decompressed. If the data needs to be transformed (for example, byte swapped), then the data elements are transformed after decompression and selection.
While an application must sometimes set up some elements of the pipeline, use of the pipeline is normally transparent to the user program. The library determines what must be done based on the metadata for the file, the object, and the specific request. An example of when an application might be required to set up some elements in the pipeline is if the application used a custom error-checking algorithm.
In some cases, it is necessary to pass parameters to and from modules in the pipeline or among other parts of the library that are not directly called through the programming API. This is accomplished through the use of dataset transfer and data access property lists.
The VFL provides an interface whereby user applications can add custom modules to the data transfer pipeline. For example, a custom compression algorithm can be used with the HDF5 Library by linking an appropriate module into the pipeline through the VFL. This requires creating an appropriate wrapper for the compression module and registering it with the library with H5Zregister. The algorithm can then be applied to a dataset with an H5Pset_filter call which will add the algorithm to the selected dataset's transfer property list.
Previous Chapter The HDF5 Data Model and File Structure - Next Chapter The HDF5 File
Navigate back: Main / HDF5 User Guide